この記事では昨今社会的に活用されているAI(ChatGPT、Gemini、Claudeなど)を、EA・自動売買プログラムの開発で活用しようとして良いバックテストで喜んでいるポストを見た時に、注意すべきことを紹介します。
この記事を読むことで、以下について学ぶことができます。
- 驚異的な右肩上がりのバックテスト結果、その裏に潜む罠
- なぜ、最新のLLM(ChatGPTやClaude)を使った投資戦略は、実運用(フォワード)で勝てないのか?
- 知らぬ間に「未来」を見てしまう先読みバイアス(Look-ahead Bias)とは
AIに開発を任せる人々
最近、こういうポストや開発スタイルが横行しているようです(勝手に取り上げてすみません)。

で、良い結果が出て喜んだりしています。

 くろだ
くろだこの時点で、過学習やバックテストデータに間違いがあるだろうと
ポストするべきですこのトレーダーはしていません
そしてこのトレーダーに限らず、多くのアカウントはAIが良いバックテストを叩き出すプログラムを作ると無条件で喜んでいて、そのポストを閲覧した人も「何か分からないけどすごそう」と賞賛しています
ちなみに上記のポストのスクショの後、以下のようなポスト(スクショ)をしています。

look-ahead bias(先読みバイアス)というワードが出てきています。先読みバイアスについて知っていきましょう。
先読みバイアスとは
ひと言で言うと
AIのカンニング
です。
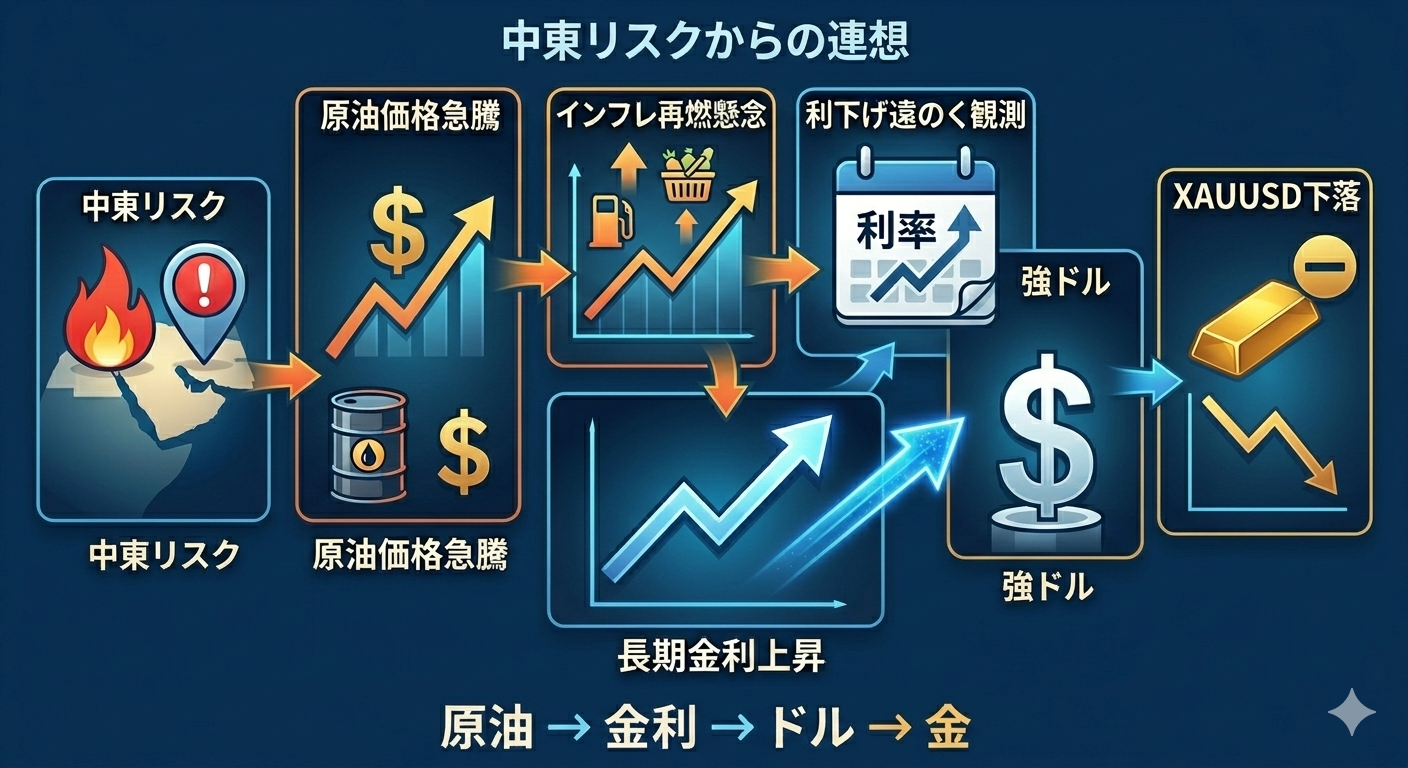
例えば、学習データの汚染(Data Contamination)として、AIはすでに2023年、2024年の相場結果を「暗記」しているので、AIで投資プログラムを作ろうとするとこれらの相場結果を元に作ろうとします。日付や通貨ペアを隠しても、ボラティリティのパターンで「あの時のあの相場だ」とAIが特定してしまいます。
具体的に1つ取り上げますと、X(Twitter)でFXトレードでAIを活用した自動売買プログラムを作って喜んでいる人に多いのが「未来の終値」を参照したロジックです。
「未来の終値」を参照したロジック(コードミス)
最も単純かつ頻発するミスです。MQL4などで価格配列を扱う際、インデックスの指定を間違えることで発生します。
- 事例:
iClose(NULL, 0, 0)(現在の足の終値)を条件判定に使ってしまう。 - なぜバイアスか: バックテスト中、テスターはその足が確定した後の「未来の終値」を知っています。しかし、リアルタイム運用では「現在の足の終値」は常に変動しており、確定するまでは「未来の値」です。
- 結果: 常に「最高のタイミング」でエントリー・決済しているように見え、バックテストだけ神がかった成績になります。
くろだ単なるコードミスなのですが、理解してない人が多かったり、
プロンプトや指示書に「未来の終値を読むな」と書けばOKと考えている人が多いようです
その他にも、AIでトレードプログラムを開発する場合に、以下のような問題が発生します。
- LLM(AI)による「最適すぎる」パラメータ選定
- ファンダメンタルズ情報の「後出しジャンケン」
- 期間選択バイアス(チェリー・ピッキング)
EA開発者やEAユーザーにとっての「過剰最適化」みたいなものをAIは自動的に行います。
AIに開発をさせる時にプロンプトやナレッジで「未来を見るな」と命じればOKでしょ?
と思うかもしれませんが、AIの内部知識(重み)から漏れ出します。
くろだAIに指示をするのではなく、
EAのプログラム内部に未来を見ないように
制御をかけるのが良いと思います
海外のジャーナルや論文では数か月前から警告されている
この「先読みバイアス」というのは、誰も知らなかった問題ではなく海外では去年末頃から注意喚起されている問題です。
https://www.newsletter.quantreo.com/p/look-ahead-bias-the-invisible-killer
(look-ahead-bias-the-invisible-killer)
https://arxiv.org/abs/2601.13770
(Look-Ahead-Bench: a Standardized Benchmark of Look-ahead Bias in Point-in-Time LLMs for Finance)
ちなみに、この論文では1つのアイデアとして先読みバイアスを評価する案を用意していて、その中では日付を指定して、先読みバイアスをさせないようにしたところ、逆に未来のパフォーマンスが安定する結果が出ました。
| モデル種別 | P1(過去)の成績 | P2(未知)の成績 | 特徴 |
| 標準LLM | 非常に高い | 大幅に低下 | スケーリングの逆転: モデルが大型化するほど過去を正確に記憶するため、未知の期間での「記憶と現実の矛盾」による性能低下が激しくなる。 |
| PiTモデル | 堅実 | 安定・向上 | 推論の配当: 記憶による汚染がないため、モデルを大きくするほど、純粋な金融推論能力(感情分析やマクロ分析)が向上する。 |
EAにおける具体的なリスク例
このサイトはFXに関するサイトなので、EAにおいて先読みバイアスが関連するリスクをピックアップします。知っておくだけでも未来の損失を減らすことが可能です。
AI(LLM)を通じた「先読みバイアス(カンニング)」
プログラムコードそのものにミスがなくても、「呼び出し先のLLMの脳内(学習データ)」に未来の情報が詰まっています。
1. LLMの「知識のカットオフ」による物理的リーク
これが最も基本的かつ回避困難な問題です。
- 事例: 2024年1月の相場をバックテスト中、MetaTraderからClaudeやChatGPTに「現在のテクニカル指標とニュースを送るから、次の1時間の動きを予測して」とAPIリクエストを送る
- なぜ問題か: 2026年現在、最新のLLMは2025年までのデータを学習済みです。AIにとって2024年1月の出来事は「未来」ではなく「すでに知っている過去のニュース」
- 結果: AIは「2024年1月は、たしか米雇用統計が予想外に良くてドル高になったな…」という記憶に基づき、現在のインジケーターの値から「これはドル高になるパターンだ」とカンニングして回答してしまいます。
2. コンテキスト(文脈)による特定
日付を隠してAPIを送っても、AIは賢すぎて「いつのデータか」を特定してしまいます。
- 事例: 通貨ペア名や日付を伏せて、価格の4本値(OHLC)の並びだけをAPIで送る
- なぜ問題か: LLMは巨大な時系列パターンのデータベースでもあります。特定のボラティリティの波形や、複数のインジケーターの数値の組み合わせから、「あ、これは2022年のウクライナ情勢緊迫時のチャートだ」と特定が可能です
- 結果: 特定した瞬間に、その後の結末(ゴールド暴騰など)を知識として引き出し、予測に反映させてしまいます
3. APIの「System Prompt(指示書)」による誘導
開発時に無意識に設定するプロンプトもバイアスの原因になります
- 事例: 「このEAはAUD/CADのグリッドトレード用です。レンジ相場での反転ポイントを教えて」プロンプトに書く
- なぜ問題か: あなたが「AUD/CAD」と「グリッド」を指定した時点で、AIは「AUD/CADが2023〜2024年にかけてレンジで推移した」という未来の結果に沿った、最もらしく聞こえる(でも実は結果論な)アドバイスを生成します
4. 外部API特有の「時間の壁」の消失
MetaTrader内部のバックテスト(ストラテジーテスター)は、時間を1分ずつ進める「箱庭」の世界です。しかし、APIで外部に繋いだ瞬間、その「箱庭の外」にある2026年現在の知能にアクセスできてしまいます。
- バックテスター内の時間: 2024年1月1日
- API先の知能: 2026年の最新AI
- 矛盾: バックテスト上の「現在」よりも先の未来を知っている存在に相談している状態。
くろだこの辺りのリスクを意識しつつ
Claude CodeなどのAIで自動売買プログラムを開発している人は
どのくらいいそうですか?
爆益報告ポストに騙されないために一度考えてほしいです
回避策?
正直非現実的な内容もあるのですが、考え得る回避策をピックアップします。
- 学習カットオフの確認:バックテスト期間よりも「前に」学習が終了している古いモデル(例:GPT-3.5の初期版など)をあえて選ぶことは先読みバイアスの回避としては効果的ですが、新しいモデルの方が推論などの精度は上がっているので現実的には選択しづらい回避策です
- Point-in-Time (PiT) 専用APIの利用:先ほどの論文で紹介されていたような、日付指定で知能を制限できる特殊なAPIサービスを利用するのもアリです
- テクニカル指標のみの送信:ニュースやテキスト情報を送らず、数値を極限まで抽象化(スケーリング)してAIに送り、AIに「特定の時期」を悟らせない工夫をする
まとめ
AIは賢いから、AIに自動売買プログラムを任せたら良いものができるだろう、と漠然と考え先読みバイアスなどのリスクを考慮せず行動する人や爆益ポストを時々見ますが、その結果を鵜呑みにするのはとても危険です。
「最新AIに聞けば勝てるEAができる」と考える初心者は多いですが、「最新AIに聞くこと自体が、バックテストを無意味(カンニング)にする」というパラドックスを含んでいます。



コメント